 如何设计合适的状态管理方案
如何设计合适的状态管理方案
在前端应用的开发过程中,对于规模较小、各个模块间依赖较少的项目,一般不会引入复杂的状态管理工具。
但实际上,业务的发展和变化很快,随着我们项目在不断地变大、各个页面中需要共享和通信的内容越来越多,与此同时项目也加入了新成员、不同开发的习惯不一致,项目到后期可能会出现事件的传递、全局数据满天飞的情况。
这样会有什么隐患呢?当我们想要改某个状态数据的时候,无法直观确认这些改动会不会影响到其他地方。更让人头疼的是,在测试的时候并没有发现存在问题(毕竟有在项目规模较大的情况下,回归测试的成本也会越来越重),然后触发了线上事故。
这是否又意味着所有项目都应该在最初的时候引入状态管理方案呢?除非项目在最初就已经定位为大型或复杂的应用,否则我们则需要根据预期来选型、根据需要引进不同的工具库来进行管理。同时,如果我们的项目在不断的发展和迭代过程中,则可能需要进行状态管理方案的变更。
关于技术选型和项目设计的内容,我会在后续介绍。因为在掌握如何进行方案选型之前,我们还需要了解现有的各种方案。所以,今天我们主要来认识下常见的前端状态管理方案。
要介绍数据在前端应用中是怎么流动的,首先我们要了解数据是如何管理的。
数据管理
一般来说,各个组件的数据都会在组件自身的实例当中进行维护。但如果一些数据涉及跨组件共享、全局共享的情况,则需要对数据进行统一的保存和维护,大多数情况下我们都会使用共享对象的方式。
共享对象
共享对象的原理很简单,当我们需要多个地方使用相同的数据,我们就把它们放置在一个地方,大家都去那里获取和更新。
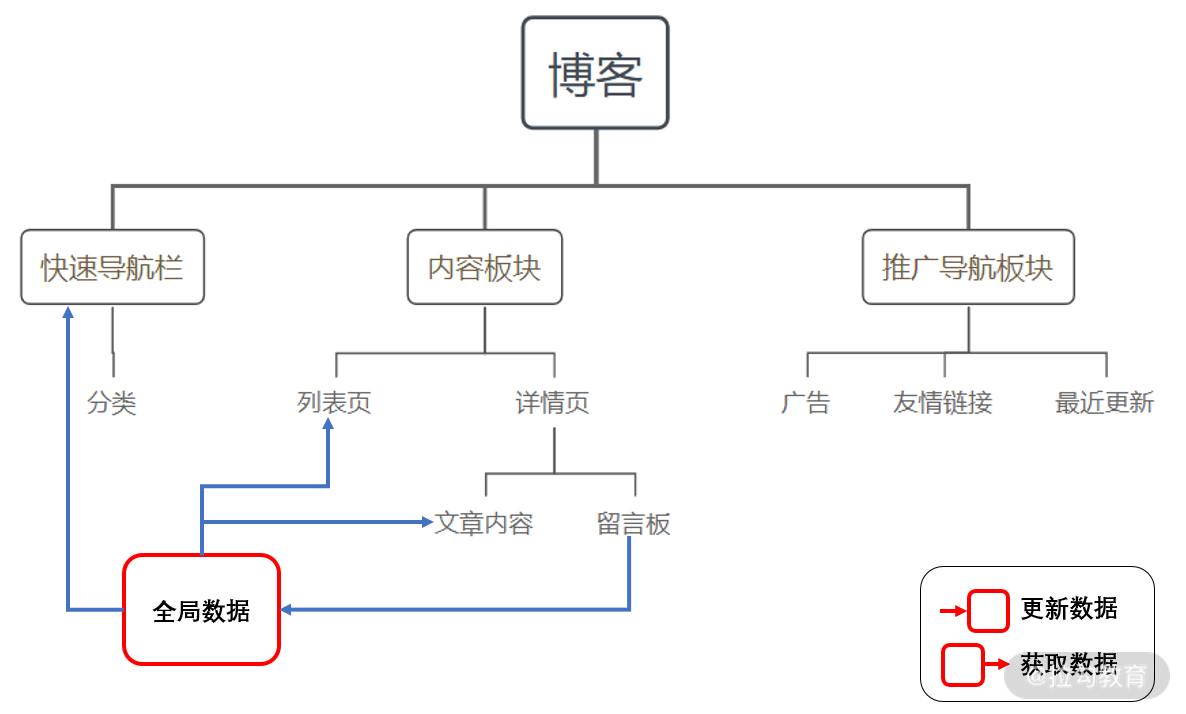
比如,我们可以简单用一个叫globalData.js的文件来管理全局用的数据。
// globalData.js
// globalData 用来存全局数据
let globalData = {};
// 获取全局数据
// 传 key 获取对应的值
// 不传 key 获取全部值
export function getGlobalData(key) {
return key ? globalData[key] : globalData;
}
// 设置全局数据
export function setGlobalData(key, value) {
// 需要传键值对
if (key === undefined || value === undefined) {
return;
}
globalData = { ...globalData, [key]: value };
return globalData;
}
除了全局数据以外,局部数据的管理同样可以使用共享对象的方式进行,我们将需要共享的数据维护在一个对象中,需要的时候则主动进行获取。
那如果应用中存在多个共享对象,我们又该怎样管理这些对象呢?
根据模块进行划分
在大型应用中,维护的全局数据也会更加复杂,通过合适的方式进行拆分,可以更方便地进行管理,比如根据数据的类型、使用场景、涉及的功能,从而拆分模块的方式来进行管理。
除此之外,我们还可以使用树状结构的方式来管理这些全局对象。
使用树状结构管理数据
在介绍第 1 讲的时候,我就有介绍前端页面中,DOM 节点是基于树状结构管理的。同时,前端应用即便通过模块化和组件化一层层地进行了封装,最终依然会呈现为树状。
因此,我们可以根据组件的树状作用域,结合共享对象的管理,来注入树状的数据结构。比如在 Angular 中,就是使用依赖注入的方式,配合树状的组件管理,来实现数据的共享或是隔离。
现在,我们知道应用中需要共享的数据可以通过怎样的方式进行管理,那么当数据发生变化的时候,又该怎样通知到依赖方吗?
数据变更
前面的第 15 讲中,我介绍了如何将应用和界面抽象成数据管理,其实被抽象的数据也就是我们常说的状态。
前端项目中的数据并不只是简单地存在于应用中,相互之间会进行交互和影响。数据间的相互作用,便是我们常说的数据通信或是状态管理,包括但不限于以下的一些方式:
事件监听与触发;
单向数据流;
响应式数据流。
我们来分别看一下。
事件监听与触发
事件监听与触发的设计,一般来说会基于发布-订阅模式。想必你也比较熟悉,我们对浏览器点击、输入框的输入操作事件的绑定,就是典型的事件机制。
我们也可以通过事件管理的方式,来进行数据的交互,比如 Websocket 机制。
事件监听和触发的原理其实很简单。监听者在进行事件监听后,会被添加到该事件的监听者队列中。事件被触发后,则可以根据该事件的监听者队列,来通知相应的监听者。
在第 1 讲中,我们介绍了事件委托机制,在很多前端框架中,事件委托会挂载在页面的组件根实例上。除了挂载在组件根实例这样的方式来绑定作为事件中心,我们也可以自行创建一个事件中心来进行管理。
事件通知机制很方便,可以随意控制触发的时机,也可以任意的地方监听或是触发。但前面也说过,事件机制的弊端也是很明显,就是每一个事件的触发对应一个或者多个监听,关系是一对多。
设计不合理的地方,甚至可能出现一个事件会被多处触发的问题,常常是事件散落在各个地方、数据流也难以跟踪。需要定位的时候,只能通过全局搜索的方式来跟踪数据的去向,导致维护难度大大上升。
以简单的博客系统来为例:
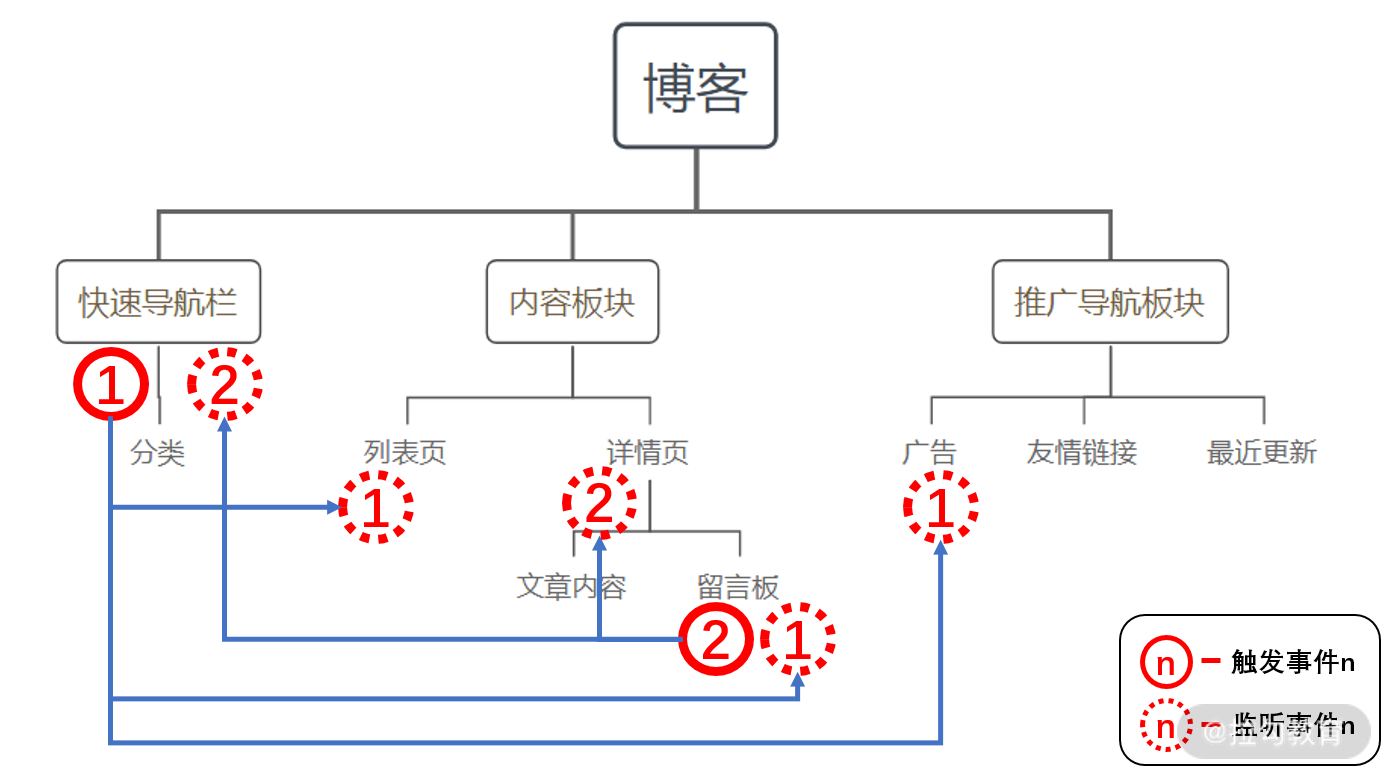
这里只有事件 1 和事件 2 的触发和监听,存在跨组件甚至跨页面的事件通知。
如果在一个规模较大的应用中,可能会导致满屏的事件,同时事件之间并没有什么规律可循。这样我们每次改动事件相关的代码,例如多传一个参数、改变某个参数,都可能会导致未知的错误,需要全局搜索出相关的事件,并一一进行回归测试才可以。
除此之外,绑定的事件如果不能及时销毁甚至会导致内存泄漏等问题。那么,是不是在大型复杂的前端应用中,就不适合使用事件机制呢?并不是。
在大型前端项目 VS Code 中就使用了事件机制,并配合依赖注入的框架设计了一套事件的管理模式,包括:
提供标准化的
Event和Emitter能力;通过注册
Emitter,并对外提供类似生命周期的方法onXxxxx的方式,来进行事件的订阅和监听;通过提供通用类
Disposable,统一管理相关资源的注册和销毁;通过使用同样的方式
this._register()注册事件和订阅事件,将事件相关资源的处理统一挂载到dispose()方法中。
由于 VS Code 中使用了依赖注入,对于模块的实例创建、销毁等都会统一交给框架来进行,从而很方便地解决了事件机制的弊端。
很多时候,我们不只是选择某个技术方案这么简单,对于方案如何在项目中落地、是否需要进行适当的调整,都是需要进行思考的。
下面我们继续看一下,在前端领域中更加普遍的状态管理方式:单向数据流。
单向数据流
如今很多前端框架都会搭配使用状态管理工具,来处理应用中的数据变更。
其中,Vuex/Redux/Flux 这些热门的状态管理工具库设计思想都基于单向数据流,它们采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。
以 Redux 为例,为了保证数据是单向流动的:
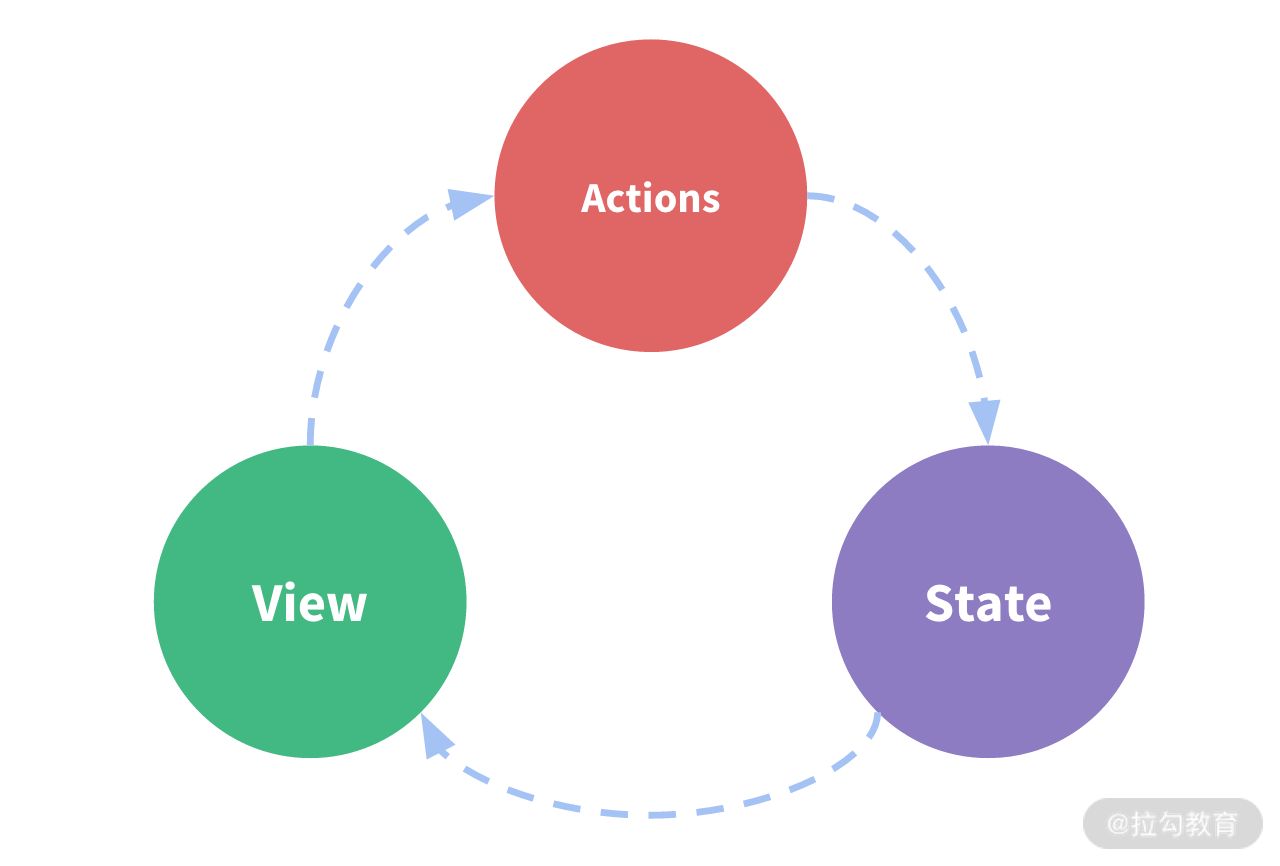
使用单一的数据源:所有的状态数据都存储在
store中;状态数据只读:只能通过
action来触发数据变更;修改无副作用:修改现有数据的副本,并通过传递副本来更新数据。
在全局数据的使用变频繁之后,我们在定位问题的时候还会遇到不知道这个数据为何改变的情况,因为所有引用到这个全局数据的地方都可能对它进行改变。
这种情况下,给数据的流动一个方向,则可以方便地跟踪数据的来源和去处。
同样以博客系统为例:
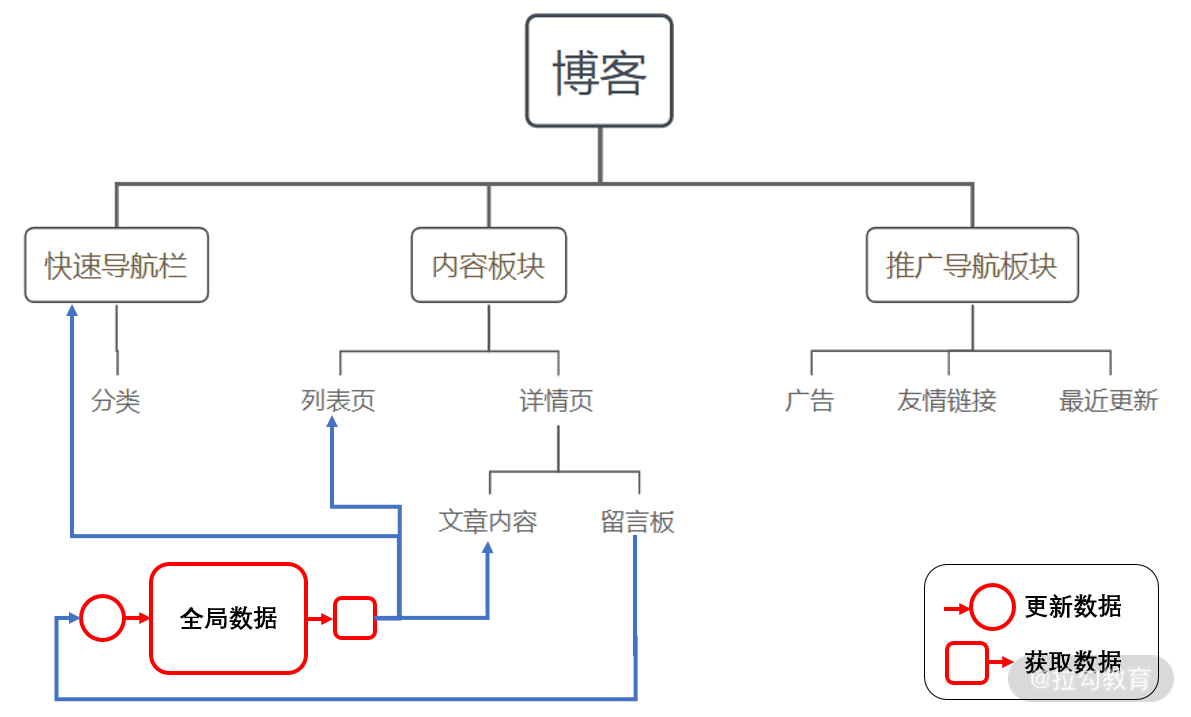
可以看到,使用了单向数据流的状态管理方案之后,数据的变更来源、更新方向都相比事件触发要清晰。因此,也被更多开发者所推崇。
除了单向数据流的方案以外,前端项目中比较热门的还有响应式的数据管理方式。
响应式数据流
响应式数据流的设计基于响应式编程方式,响应式编程同样基于观察者模式,它是一种面向数据流和变化传播的声明式编程方式。在前端领域,常见的异步编程场景包括事件处理、用户输入、HTTP 响应等。
对于这样的异步数据流,可以使用响应式编程的方式来进行设计,通过订阅某个数据流,可以对数据进行一系列流式处理,例如过滤、计算、转换、合流等,配合函数式编程可以实现很多优秀的场景。
以 Rxjs 为例,对用户的一些交互,也可以通过订阅的方式来获取需要的信息:
const observable = Rx.Observable.fromEvent(input, "input") // 监听 input 元素的 input 事件
.map((e) => e.target.value) // 一旦发生,把事件对象 e 映射成 input 元素的值
.filter((value) => value.length >= 1) // 接着过滤掉值长度小于 1 的
.distinctUntilChanged() // 如果该值和过去最新的值相等,则忽略
.subscribe(
// subscribe 拿到数据
(x) => console.log(x),
(err) => console.error(err)
);
// 订阅
observable.subscribe((x) => console.log(x));
Angular 框架本身推荐使用的状态管理工具便是 Rxjs,在 Angular 中结合依赖注入的方式,来进行数据流的订阅和触发,也可以很方便地对数据源和流向进行管理。
除了 Rxjs,基于响应式数据流设计的状态管理库包括还有 Mobx。其中,Rxjs 提供了基于可观察对象(Observable)的响应式服务,Mobx 提供了基于状态管理的响应式服务。基于响应式数据流的设计,我们可以通过各种合流的方式、订阅分流的方式,来将应用中的数据流动从头到尾串在一起。这样,我们可以很清晰地知道当前节点上的数据来自哪里,是用户的操作还是来自网络请求。
对于很多复杂程度较低的前端应用来说,响应式数据流的入门成本比较高。但在一些复杂应用的场景,合理地使用响应式编程,可以有效地降低各个模块间的依赖,更加容易地进行整体数据流动管理和维护。
除了天然异步的前端、客户端等 GUI 开发以外,响应式编程在大数据处理中也同样拥有高并发、分布式、依赖解耦等优势,在这种同步阻塞转异步的并发场景下会有较大的性能提升,淘宝业务架构就是使用响应式的架构。
小结
我们的项目里,常常会面临应用中某些状态和数据相互影响、相互依赖的问题。
今天我介绍了一些常见的状态管理的解决方案,包括事件监听、单向数据流、响应式数据流等。那么,它们之间有明显的优劣吗?
其实最终还是取决于项目本身的架构、业务场景,对于简单的项目来说,使用事件监听就可以方便地解决父子组件通信的问题;当项目规模增加之后,则可能面临全局事件乱飞的问题,此时使用单向数据流或是响应式数据流的方式都可以解决该问题。
实际上,复杂的前端项目中常常会同时存在多种状态管理方式,同时也会结合业务本身进行适当的调整。除了选择合适的状态管理方案以外,我们还可以通过设计合理的状态来简化一些复杂的问题场景,比如来解决前端常见的防抖和节流问题,同样可以设计状态机的方式来解决。
我们在思考如何解决问题的同时,还可以找到问题的根源,并尝试分析和解决。只有这样,我们才可以脱离被层出不穷的问题缠身的状况,更加专注地进行项目优化。
除了本文介绍的,你还了解到哪些状态管理的方式呢?欢迎在留言区进行讨论~
# 精选评论
# **哈:
问几个问题:Vuex:1. 为什么mutation中只能是同步?2. 为什么必须通过commit mutation的方式更改stateRedux:1. 为什么reducer必须是纯函数?2. 为什么reducer必须返回新的state,而不可以修改原有state?